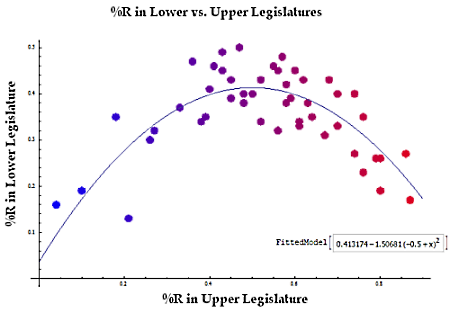
Earthquakes vs. Time of Day
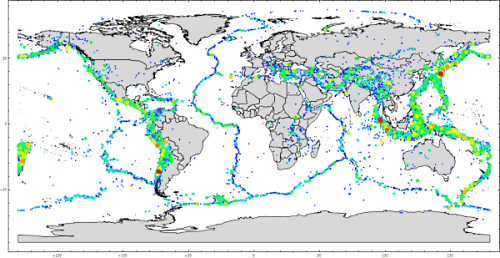
Time and tide wait for no one. Add to that: earthquakes. I live in the San Francisco Bay Area, a.k.a. “earthquake country”, in a house built in the 1950s before earthquake building codes had been created. Within the next 30 years, the USGS tells us we can expect a “big one” in the East Bay …