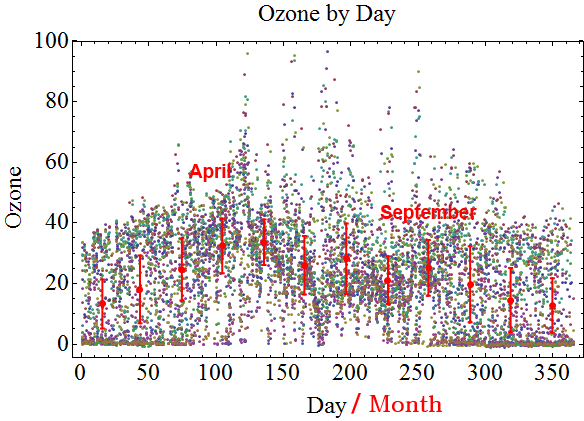
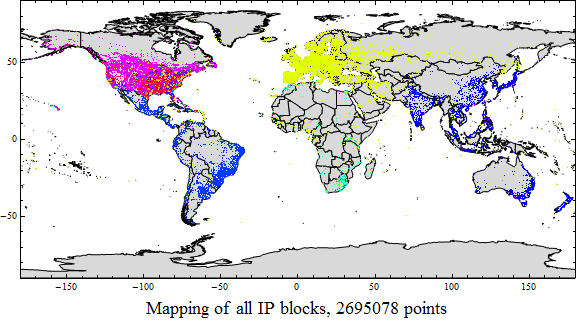
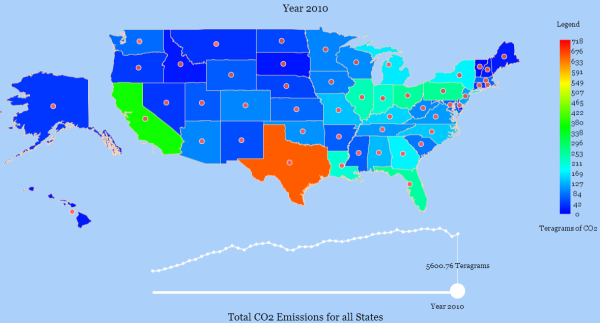
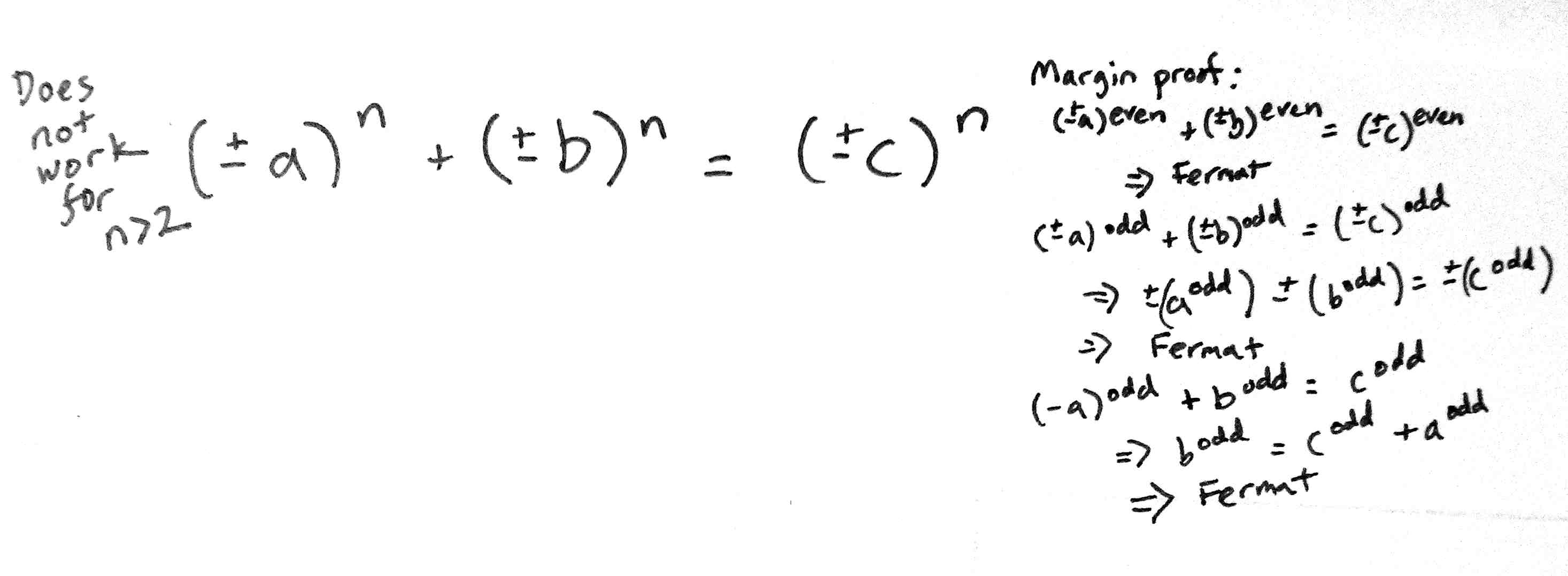ZeroDivZero is here!
I wanted to update everyone with news about a science conference website I have built: https://zerodivzero.com The website allows users to upload papers to their accounts and then search for science conferences to submit to. Keep track of all your acceptances, rejections, reviews and comments from your profile page. The site is fairly new and …